
8 scientific challenges on the global approach for AI components with controlled trust
We are starting a series of articles to present the scientific challenges identified by Confiance.ai members. For the Confiance.ai program, a scientific challenge is a subject on which there is no complete solution (methods, algorithms, ready-to-use tools) and which therefore requires additional research. There may be partial solutions, for example described in scientific publications, or even implemented within software tools, but these solutions cannot be used as they are and only resolve part of the subject. The challenges were built little by little from an initial version created by the Scientific Department of IRT SystemX before the start of Confiance.ai, updated following the state of the art made in the projects and recently completed by a dozen challenges identified internally by our partner Airbus.
The task is large because to date we have more than 75 individual challenges, grouped into large categories (software components, data, interaction) and nine subcategories. The mindmap below shows this hierarchy.
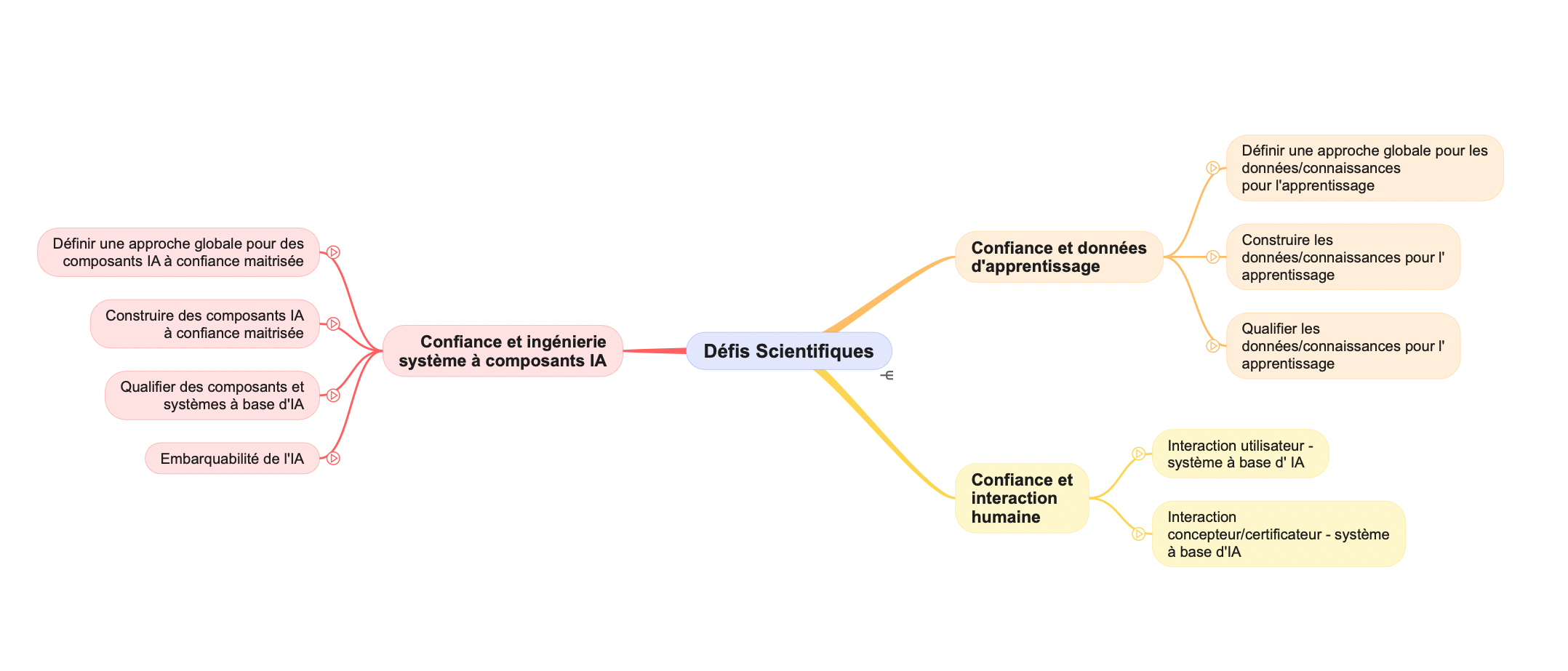
It will take several articles in the series to present all the scientific challenges. Today, we start with the subcategory “Components/Overall approach for trust-controlled AI components”, which presents the generic challenges for these components, whether they are their design, their evaluation or their deployment in general or embedded hardware architectures.
The global approach for AI components with controlled trust
In this category, we currently have eight scientific challenges, unranked (the order of presentation below has no particular meaning).
1. The methodology for defining the desired behavior of the trusted AI system
A great subject! Very often, the objectives of a trusted AI system are implicit, not formalized, particularly in the case of machine learning. Some objectives are found in a utility function to be maximized, others are probably coded in the software used, but today we do not have a general method for defining the desired behavior of an AI system, even if it There is an abundant literature on the subject. For example, a system which minimizes the overall classification error on the basis of examples has no objective concerning the reduction of bias… hence the numerous debates and works on this subject.
2. Specifications of trusted AI systems based on functional and non-functional requirements
A byproduct of the previous challenge. The system approach makes it possible to define functional and non-functional requirements; there are numerous formalisms for this, whether formal, logical, graphic, ontological, from software engineering methods (UML in particular). The subject is to transform these functional and non-functional requirements into specifications for our trusted AI system, which cannot directly use the models from previous formalisms. Here again, a lot of research work needs to be done to facilitate this transition from one to the other.
3. Defining the operational domain during the life cycle of the AI system
The operational domain is that for which the AI system is designed: within this domain, operation is assumed to be nominal, no guarantee can be provided to the exterior. For example, for an autonomous driving system – one of the first examples for which this notion was developed – there may be conditions of sunlight, visibility, nature of roads, etc. It is therefore important to be able to define the domain of use (for example by constraints relating to environmental data), but also to verify that the AI system continues to be applied within this domain, otherwise from which it is better to unplug it. Defining the operational domain and monitoring it are important scientific challenges.
4. How to include human and societal factors in the ODD?
The ODD is a key concept in the safe deployment of AI systems. If we think quite naturally of environmental factors (see the example of the autonomous vehicle above) or of implementation factors (for example the operating condition of a camera to detect manufacturing imperfections ), there can also be human factors which condition the use of an AI system – we can think of the example of driving assistance systems where a constraint on the driver’s state of fatigue would prohibit to carry out certain operations.
These first challenges are also important for some of the questions of validation of AI systems (compliance with specifications, use within the field of employment). The specific validation challenges will be presented later in the article on the scientific challenge “qualifying AI-based components and systems”.
5. The methodology for identifying risks in the case of trusted AI systems
As with all technological systems, the use of AI systems involves risks; This is also the point of view of the European Commission which structures its future AI regulations on the level of risk. The risk factors are numerous: technological (robustness, reliability, precision, security, etc.) but also human (are the systems correctly implemented, are the people involved sufficiently involved?), governance (has have the mechanisms been put in place to control the application?) to name just a few. European regulations will require that a risk analysis be carried out before putting into service a system considered to be high risk, hence the importance of having a methodology to do this. A good practice is to start from a list of risk categories: such a list is being established within the framework of the harmonized standards on AI of the European Commission.
6. Risk mitigation methodology in the case of trusted AI systems
It is not enough to identify risks: they must also be controlled, which involves developing mitigation means. For example, for technological risks, we can implement algorithmic mitigations (adversarial learning, ensemble methods, etc., it is not the purpose of this short paragraph to detail all of that); for human risks, mitigation can involve operator training and the development of suitable human-machine interfaces); in any case once the main risks have been identified, it is important to examine the mitigation possibilities to reduce them.
7. How to deal with the weaknesses of machine learning models (approximation, generalization, optimization errors) at the system architecture level?
This challenge concerns well-known weaknesses (but for which we do not have off-the-shelf solutions) of machine learning models. As explained above, we can think of local algorithmic solutions to compensate for these weaknesses, but here we are talking about solutions at the level of the system architecture: for example, setting up redundancies (several systems to ensure the same function ), carry out special processing of the outputs of the AI system, or systematically request validation by a human operator, all things that can be anticipated when designing the architecture of the system.
8. Model and data lifecycle management for large machine learning applications
A challenge more technological than scientific. Some machine learning applications handle very large volumes of data and very large models: it is necessary to ensure that all solutions are well implemented to guarantee their life cycle: availability of sufficient resources for storage and calculation ( including resources distributed over several servers), scripts allowing certain tasks to be automated, means of traceability, etc.