
8 défis scientifiques sur l’approche globale pour des composants d’IA à confiance maitrisée
Nous entamons une série d’articles pour présenter les défis scientifiques identifiés par les membres de Confiance.ai. Pour le programme, un défi scientifique est un sujet sur lequel il n’existe pas de solution complète (méthodes, algorithmes, outils prêts à l’emploi) et qui demande donc des recherches complémentaires. Il peut exister des solutions partielles, par exemple décrites dans des publications scientifiques, voire mises en œuvre au sein d’outils logiciels, mais ces solutions ne sont pas utilisables telles quelles et ne résolvent qu’une partie du sujet. Les défis ont été construits petit à petit à partir d’une version initiale créée par la Direction Scientifique de l’IRT SystemX avant le démarrage de Confiance.ai, mise à jour suite aux états de l’art faits dans les projets et récemment complétée par une douzaine de défis identifiés en interne par notre partenaire Airbus.
La tâche est d’ampleur car nous avons à ce jour plus de 75 défis individuels, regroupés en grandes catégories (composants logiciels, données, interaction) et neuf sous-catégories. La mindmap ci-dessous montre cette hiérarchie.
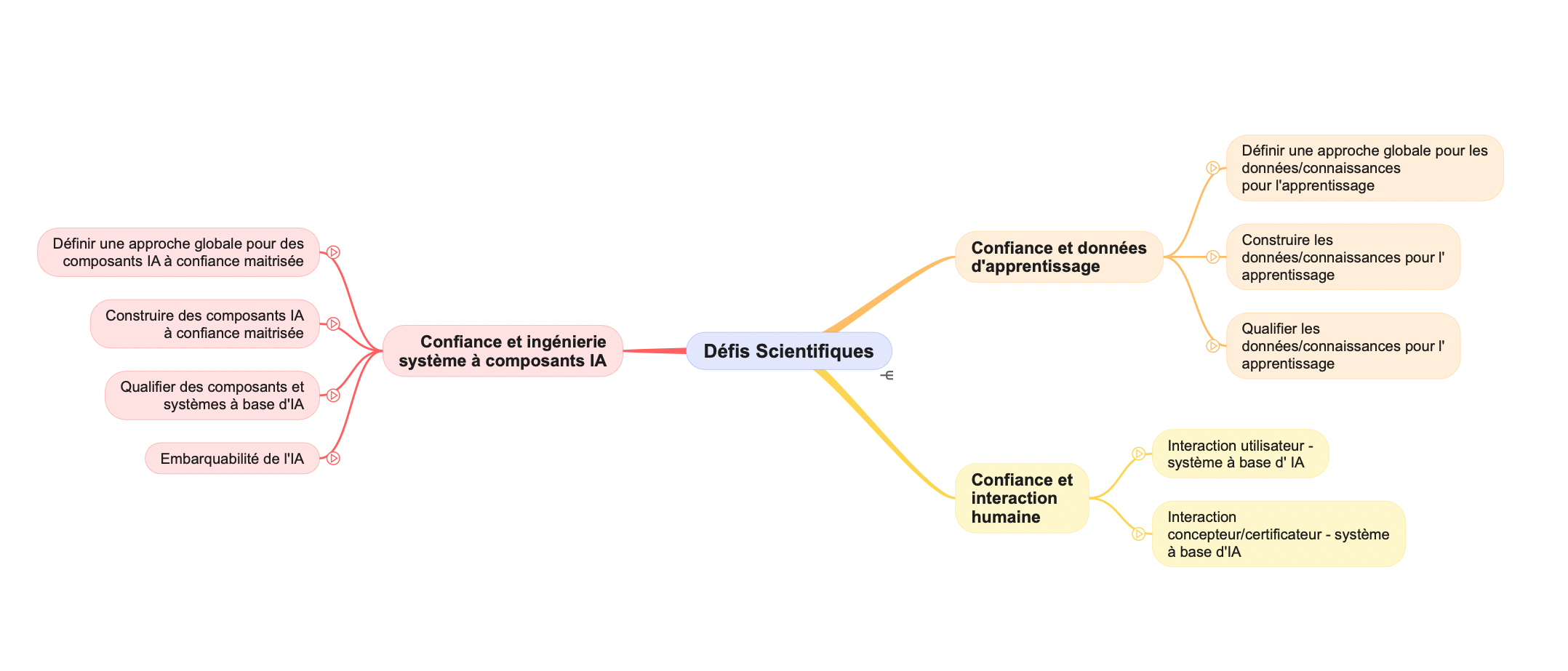
Il faudra plusieurs articles dans la série pour présenter tous les défis scientifiques. Aujourd’hui, nous commençons par la sous-catégorie « Composants/Approche globale pour des composants IA à confiance maitrisée », qui présente les défis génériques pour ces composants, qu’ils s’agissent de leur conception, de leur évaluation ou de leur déploiement dans des architectures matérielles générales ou embarquées.
L’approche globale pour des composants d’IA à confiance maitrisée
Dans cette catégorie, nous avons actuellement huit défis scientifiques, non classés (l’ordre de présentation ci-dessous n’a pas de sens particulier).
1. La méthodologie de définition du comportement désiré du système d’IA de confiance
Un grand sujet ! Très souvent, les objectifs d’un système d’IA de confiance sont implicites, non formalisés, en particulier dans le cas de l’apprentissage automatique. Certains objectifs se trouvent dans une fonction utilité à maximiser, d’autres probablement codés dans les logiciels utilisés mais on ne dispose pas aujourd’hui d’une méthode générale de définition du comportement désiré d’un système d’IA, même s’il existe une abondante littérature sur le sujet. Par exemple, un système qui minimise l’erreur globale de classement sur une base d’exemples n’a pas d’objectif concernant la réduction des biais … d’où les nombreux débats et travaux à ce sujet.
2. Les spécifications de systèmes d’IA de confiance à partir des exigences fonctionnelles et non fonctionnelles
Un sous-produit du défi précédent. L’approche système permet de définir les exigences fonctionnelles et non fonctionnelles, il existe de nombreux formalismes pour cela, qu’ils soient formels, logiques, graphiques, ontologiques, issus des méthodes de génie logiciel (UML en particulier). Le sujet est de transformer ces exigences fonctionnelles et non fonctionnelles en spécifications pour notre système IA de confiance, qui ne peut pas directement utiliser les modèles issus des formalismes précédents. Là encore, beaucoup de travail de recherche est à conduire pour faciliter ce passage de l’un à l’autre.
3. La définition du domaine opérationnel au cours du cycle de vie du système d’IA
Le domaine opérationnel ou domaine d’emploi (en anglais ODD, Operational Design Domain) est celui pour lequel le système d’IA est conçu : à l’intérieur de ce domaine, le fonctionnement est supposé nominal, aucune garantie ne peut être fournie à l’extérieur. Par exemple, pour un système de conduite autonome – un des premiers exemples pour lesquels cette notion a été développée – il peut y avoir des conditions d’ensoleillement, de visibilité, de nature de voies etc. Il est donc important de pouvoir définir le domaine d’emploi (par exemple par des contraintes portant sur les données d’environnement), mais aussi de vérifier que le système d’IA continue à être appliqué à l’intérieur de ce domaine, faute de quoi il vaut mieux le débrancher. La définition du domaine opérationnel et son suivi sont des défis scientifiques importants.
4. Comment inclure les facteurs humains et sociétaux dans l’ODD ?
L’ODD est une notion clé dans le déploiement sûr des systèmes d’IA. Si l’on pense assez naturellement aux facteurs d’environnement (voir l’exemple du véhicule autonome ci-dessus) ou à des facteurs de mise en œuvre (par exemple la condition d’exploitation d’une caméra pour détecter des imperfections de fabrication), il peut également y avoir des facteurs humains qui conditionnent l’emploi d’un système d’IA – on peut penser à l’exemple des systèmes d’aide à la conduite où une contrainte sur l’état de fatigue du conducteur interdirait d’exécuter certaines opérations.
Ces premiers défis sont aussi importants pour une partie des questions de validation des systèmes d’IA (respect des spécifications, utilisation à l’intérieur du domaine d’emploi). Les défis spécifiques de validation seront présentés ultérieurement dans l’article sur le défi scientifique « qualifier des composants et systèmes à base d’IA ».
5. La méthodologie d’identification des risques dans le cas des systèmes d’IA de confiance
Comme pour tous les systèmes technologiques, l’emploi des systèmes d’IA comporte des risques ; c’est d’ailleurs le point de vue de la Commission Européenne qui structure sa future réglementation de l’IA sur le niveau de risque. Les facteurs de risque sont nombreux : technologiques (robustesse, fiabilité, précision, sécurité etc.) mais aussi humains (les systèmes sont-ils correctement mis en œuvre, les personnes intéressées sont-elles suffisamment impliquées ?), de gouvernance (a-t-on mis en place les mécanismes permettant de contrôler l’application ?) pour n’en citer que quelques-uns. La réglementation européenne va imposer qu’une analyse de risques soit faites avant de mettre en service un système considéré comme à haut risque d’où l’importance de disposer d’une méthodologie pour ce faire. Une bonne pratique est de partir d’une liste de catégories de risques : une telle liste est en cours d’établissement dans le cadre des normes harmonisées sur l’IA de la Commission Européenne.
6. La méthodologie de mitigation des risques dans le cas des systèmes d’IA de confiance
Il ne suffit pas d’identifier les risques : encore faut-il aussi les maîtriser, ce qui passe par le développement de moyens de mitigation. Par exemple, pour des risques technologiques, on peut mettre en place des mitigations algorithmiques (apprentissage adverse, méthodes ensemblistes etc., ce n’est pas l’objet de ce petit paragraphe de détailler tout cela) ; pour des risques humains la mitigation peut passer par de la formation des opérateurs, par des développements d’interfaces humain-machine adaptées) ; en tous cas une fois les principaux risques identifiés, il est important d’examiner les possibilités de mitigation permettant de les réduire.
7. Comment faire face aux faiblesses des modèles de machine learning (erreurs d’approximation, de généralisation, d’optimisation) au niveau de l’architecture du système ?
Ce défi concerne des faiblesses bien connues (mais pour lesquelles on ne dispose pas de solutions sur étagère) des modèles de machine learning. Comme expliqué ci-dessus, on peut penser à des solutions algorithmiques locales pour compenser ces faiblesses, mais ici on parle de solutions au niveau de l’architecture du système : par exemple, mettre en place des redondances (plusieurs systèmes pour assurer la même fonction), faire un traitement particulier des sorties du système d’IA, ou demander systématiquement la validation par un opérateur humain, toutes choses que l’on peut prévoir lorsque l’on conçoit l’architecture du système.
8. La gestion du cycle de vie des modèles et des données pour les grandes applications de machine learning
Un défi plus technologique que scientifique. Certaines applications de machine learning manipulent de très grands volumes de données et de très grands modèles : il faut s’assurer que toutes les solutions sont bien mises en place pour garantir leur cycle de vie : disponibilité de ressources suffisantes pour le stockage et le calcul (y compris ressources réparties sur plusieurs serveurs), scripts permettant d’automatiser certaines tâches, moyens de traçabilité etc.